Proto-Danksharding: Speeding Up Blobs Verification
Learn how we sped up batched blob KZG proof verification by 161.11%
May 27, 2023
rust
ethereum
eip-4844
kzg-proofs
bls12-381
CONTENTS
Introduction
The Ethereum Foundation proposed
Next week, I will be defending my thesis titled “Parallelization of the KZG10 scheme”. In my thesis, I parallelized the KZG commitment scheme and BLS12-381 elliptic curve operations, along with a subset of the EIP-4844 proposal that uses these KZG commitments. My changes were incorporated into the
How c-kzg-4844 does things
C-kzg-4844 leaves the implementation of parallelism to higher-level programming languages that use its bindings. This approach is not only simpler but also safer. The focus of c-kzg-4844 is on single-core performance, which is great for a low-latency environment.
How go-kzg-4844 does things
Go-kzg-4844 offers the function VerifyBlobKZGProofBatch, which is designed for single-core execution similar to c-kzg-4844. However, they also provide a parallelized version of this function called VerifyBlobKZGProofBatchPar. This parallelized version uses go-routines to process each proof in parallel. Although not perfect, this parallel implementation is considerably faster than the sequential one.
How we do things in rust-kzg
The general idea behind our approach is as follows: if the number of blobs exceeds the number of physical CPU cores, we divide the blobs into subgroups of equal size. Each CPU core then independently runs the batched algorithm. For example, consider the illustration below. If there are 64 blobs and 4 CPU cores, we create 4 groups, each containing 16 blobs. Each group is assigned to its dedicated CPU core, which handles the execution of the blob verification process. By utilizing this approach, we effectively distribute the workload across multiple CPU cores, optimizing performance and ensuring efficient verification of the blobs.
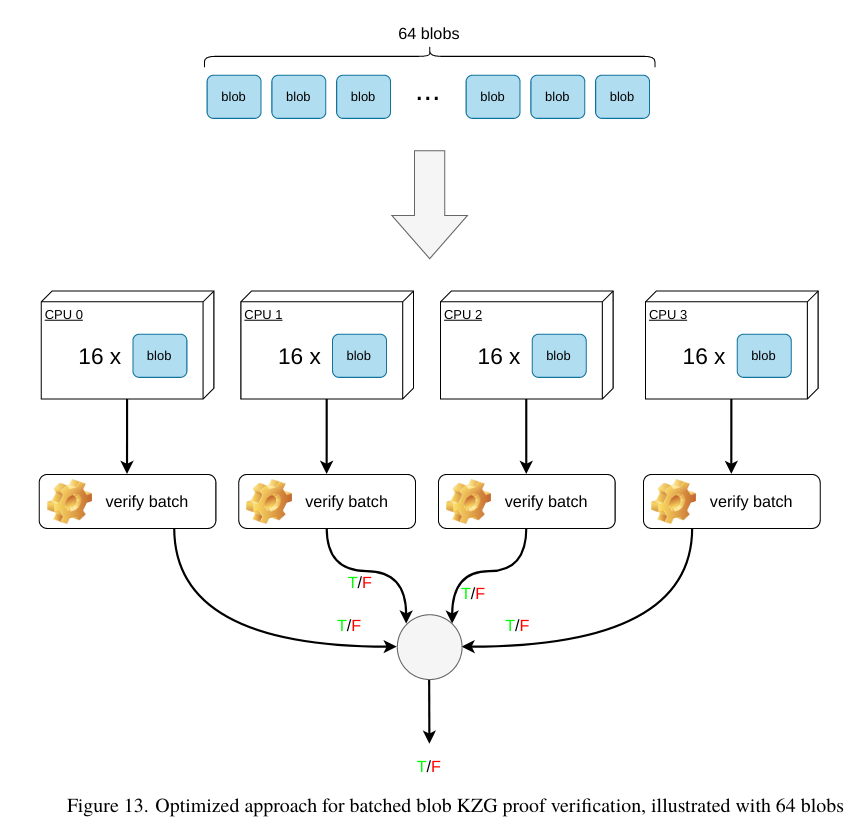
However, one could argue that the performance of batched blob KZG proof verification depends on how Ethereum protocol execution clients choose to utilize this approach. If clients choose to verify blobs as soon as they receive them, they would likely opt for an approach that performs single blob verification faster. However, if they decide to wait and accumulate a fixed amount of blobs before performing the verification, this approach will yield much better performance.
Code example
In the code snippet, there is more to the implementation, but let’s focus on illustrating the main concept of this approach:
1#[cfg(feature = "parallel")]
2{
3 let num_blobs = blobs.len();
4 let num_cores = num_cpus::get_physical();
5
6 return if num_blobs > num_cores {
7 // Process blobs in parallel subgroups
8 let blobs_per_group = num_blobs / num_cores;
9
10 blobs
11 .par_chunks(blobs_per_group)
12 .enumerate()
13 .all(|(i, blob_group)| {
14 let num_blobs_in_group = blob_group.len();
15 let commitment_group = &commitments_g1
16 [blobs_per_group * i..blobs_per_group * i + num_blobs_in_group];
17 let proof_group =
18 &proofs_g1[blobs_per_group * i..blobs_per_group * i + num_blobs_in_group];
19 let (evaluation_challenges_fr, ys_fr) =
20 compute_challenges_and_evaluate_polynomial(
21 blob_group,
22 commitment_group,
23 ts,
24 );
25
26 verify_kzg_proof_batch(
27 commitment_group,
28 &evaluation_challenges_fr,
29 &ys_fr,
30 proof_group,
31 ts,
32 )
33 })
34 } else {
35 // Each group contains either one or zero blobs, so iterate
36 // over the single blob verification function in parallel
37 (blobs, commitments_g1, proofs_g1)
38 .into_par_iter()
39 .all(|(blob, commitment, proof)| {
40 verify_blob_kzg_proof(blob, commitment, proof, ts)
41 })
42 };
43}
When num_blobs > num_cores, the code divides the blobs into parallel subgroups. The number of blobs per group is calculated based on the division. The code then iterates over each subgroup, performing various operations such as retrieving the corresponding commitment and proof groups. It also computes evaluation challenges and evaluates a polynomial using the provided data. Finally, it verifies a batch of KZG proofs using the obtained information.
In the else statement, when the number of blobs is not greater than the number of cores, the code handles each blob individually or in groups with only one blob. It uses parallel iteration to execute the blob verification function concurrently, similar to how go-kzg-4844 handles parallelism using go-routines.
Results
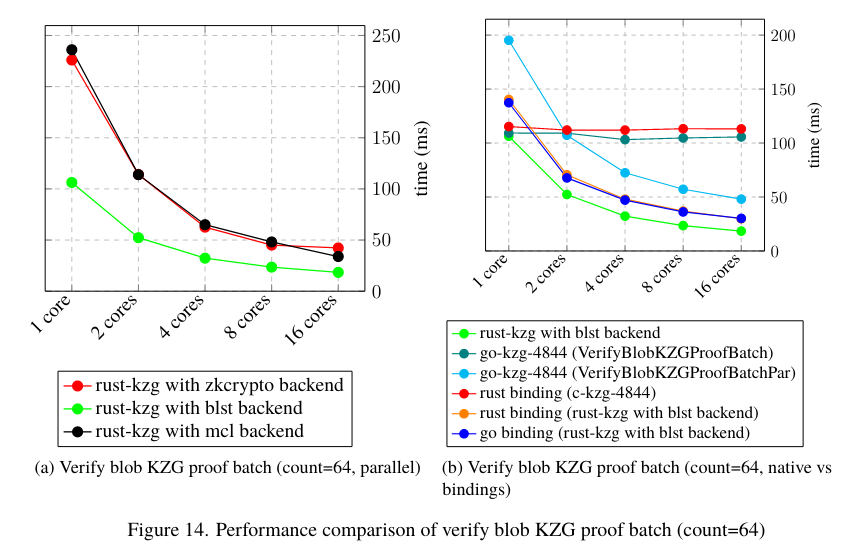
Rust and Go bindings, using the rust-kzg with blst backend, verified 64 blobs on 16 cores in 29.82 ms and 30.164 ms, respectively. In comparison, the native rust-kzg accomplished this task in 18.397 ms, while the parallelized implementation of go-kzg-4844 took 48.037 ms. It’s important to note that we only perform full error checking through the exported C API when we convert bytes to our internal types. Therefore, the performance of the native rust-kzg code is probably better because we omit those checks here, assuming we receive correct data from the byte conversion functions. With this in mind, the
Summary
- We potentially outperform go-kzg-4844 by approximately 59.25% within Go in batched blob KZG proof verification
